 88.000 VNĐ
88.000 VNĐ
ROC (Receiver operating characteristic) là một đồ thị được sử dụng khá phổ biến trong validation các model phân loại nhị phân. Đường cong này được tạo ra bằng cách biểu diễn tỷ lệ dự báo true positive rate (TPR) dựa trên tỷ lệ dự báo failse positive rate (FPR) tại các ngưỡng Threshold khác nhau. Trong machine learning Chúng ta gọi true positive rate là độ nhạy sensitivity tức là xác xuất dự báo đúng một sự kiện là positive. Tỷ lệ false positive rate là probability of false alarm (tỷ lệ cảnh báo sai, một sự kiện là negative nhưng coi nó là positive) và tỷ lệ này tương ứng với xác xuất mắc sai lầm loại II sẽ được trình bày bên dưới. Như vậy ROC curve sẽ thể hiện mối quan hệ, sự đánh đổi và ý nghĩa lựa chọn một model phù hợp của độ nhạy và tỷ lệ cảnh báo sai. Nhằm tạo ra một cái nhìn tổng quan nhất về ROC, bài viết này sẽ giới thiệu đến bạn đọc thế nào là ROC, ý nghĩa học thuật và cách lựa chọn model dựa trên ROC.
I. Sai lầm loại I, II trong dự báo.
Xác xuất mắc sai lầm loại I và loại II trong dự báo được nhắc đến khá nhiều trong các tài liệu thống kê học và đây là những loại sai lầm đặc trưng cơ bản trong các model dự báo. Giả sử chúng ta xét một model dự báo sự kiện với 2 khả năng positive (tích cực) và negative (tiêu cực). Các kết quả của model xảy ra sẽ rơi vào 4 nhóm sau:
- TP: True positive, dự báo đúng sự kiện là positive trong trường hợp thực tế là positive.
- FP: False positive, dự báo sai sự kiện là positive trong trường hợp thực tế là negative.
- TN: True negative, dự báo đúng sự kiện là negative trong trường hợp thực tế là negative.
- FN: False negative, dự báo sai sự kiện là negative trong trường hợp thực tế là positive.
TP và TN là những case dự báo đúng. Còn FP, FN là những case dự báo sai. FN tương đương với mắc sai lầm loại I (Bác bỏ sự kiện là positive và gán cho nó là negative) và FP tương đương với mắc sai lầm loại II (Chấp nhận một sự kiện là positive khi bản chất sự kiện và negative). Thông thường xác xuất mắc sai lầm loại II sẽ gây ra hậu quả lớn hơn. Mục đích chính của các model chuẩn đoán, cảnh báo hay quản trị rủi ro là cảnh báo sớm, phòng ngừa, loại bỏ các sự kiện xấu nên việc tìm chính xác được sự kiện negative được ưu tiên hơn positive. Để hiểu hơn tại sao mức độ rủi ro của sai lầm loại II là cao hơn loại I chúng ta phân tích ví dụ thực tế sau.
Bệnh tiểu đường khá nguy hiểm nhưng xác xuất mắc bệnh của loại bệnh này đối với tỷ lệ dân số là rất thấp chẳng hạn 1:10000. Một người có các biểu hiện tiểu đường và thực hiện các xét nghiệm. Sau khi xem kết quả chúng ta giả định rằng bác sĩ kết luận sai. Khi đó có 2 khả năng xảy ra:
-
Loại I: Bản thân bệnh nhân hoàn toàn bình thường, bác sĩ kết luận bệnh nhân bị tiểu đường.
-
Loại II: Bệnh nhân bị tiểu đường nhưng bác sĩ kết luận hoàn toàn bình thường.
Rõ ràng sai lầm loại II gây ra hậu quả lớn hơn vì bệnh nhân không phát hiện sớm bệnh của mình để điều trị kịp thời sẽ dẫn đến bệnh phát triển xấu đi. Sai lầm loại I có ảnh hưởng tới chi phí khám chữa bệnh nhưng không ảnh hưởng đến sức khỏe và hậu quả là ít nghiêm trọng hơn.
Căn cứ vào mức độ rủi ro này đôi khi chúng ta sẽ lựa chọn model dựa trên tiêu chuẩn mức độ thiệt hại mang lại là thấp nhất mà không phải là các chỉ số đo lường sức mạnh của model như AUC, Gini, Accuracy rate. Chẳng hạn như nếu một model dự báo nợ xấu khách hàng có xác xuất dự báo chính xác tốt hơn nhưng khi áp dụng model giá trị nợ xấu giảm thiểu của nó thấp hơn một model khác có xác xuất dự báo chính xác kém hơn thì vẫn lựa chọn model thứ 2 bởi mặc dù dự báo kém hơn về tổng thể (bao gồm cả trường hợp dự báo đúng khách hàng vỡ nợ và không vỡ nợ) nhưng tỷ lệ dự báo chính xác các hợp đồng vỡ nợ của nó cao hơn. Như vậy nếu coi xác xuất dự báo đúng là cố định thì luôn có sự đánh đổi giữa việc dự báo đúng các trường hợp tốt và dự báo đúng nguy cơ xấu. Hay nói cách khác khi tỷ lệ chính xác dự báo nguy cơ xấu tăng lên thì tỷ lệ dự báo chính xác trường hợp tốt giảm xuống. Vì mức độ quan trọng của việc lựa chọn mục tiêu mô hình là tập trung vào dự báo nguy cơ xấu hay tốt mà thống kê học đưa ra một vài tham số đo lường các tỷ lệ dự báo như sensitivity, specificity.
II. Sensitivity, Specitivity và False positive rate
- 1.Độ nhạy model (sensitivity):
Độ nhạy model còn được gọi là TPR(True positive rate) cho biết mức độ dự báo chính xác trong nhóm sự kiện positive.
Sensitivity = Số lượng sự kiện positive được dự báo đúng là positive/Số lượng sự kiện positive.
- 2.Độ đặc hiệu (Specificity):
Trái lại với Sensitivity là Specificity được định nghĩa là tỷ lệ dự báo chính xác trong nhóm sự kiện negative.
Specificity = Số lượng sự kiện negative được dự báo đúng là negative/số lượng sự kiện negative.
- 3.Xác xuất mắc sai lầm loại II (False positive rate):
False positive rate kí hiệu là FPR có công thức:
FPR = 1-Specificity.
Cho biết mức độ dự báo sai một sự kiện khi nó là negative nhưng kết luận là positive. False positive rate chính là tỷ lệ mắc sai lầm loại II và là mục tiêu để các model quản trị rủi ro tối thiểu hóa nó. Bảng bên dưới sẽ cho chúng ta hình dung rõ hơn về cách tính và mối liên hệ của các chỉ số này.

Confusion matrix
Thông thường các khía cạnh dự báo của một model mà chúng ta quan tâm sẽ tập trung vào 2 tỷ lệ: Sensitivity và False positive rate. Vì vậy cần một đồ thị biểu diễn mối liên hệ giữa chúng. ROC là một model đặc thù thể hiện các tỷ lệ này theo những ngưỡng Threshold.
III. Đường cong ROC (Receiver operating characteristic).
1. Đồ thị ROC là gì?
Dựa trên model logistic, sau khi hồi qui chúng ta sẽ thu được các điểm số của biến được dự báo. Nếu thiết lập một điểm cutpoint cho model ta sẽ có một ngưỡng để đánh giá model dự báo ra kết quả positive hay negative. Đồ thị ROC sẽ biểu diễn với mỗi điểm cutpoint ứng với nó sẽ có tỷ lệ Sensitivity và False positive rate là bao nhiêu. Trong đó trục tung ứng với tỷ lệ Sensitivity và trục hoành ứng với tỷ lệ False positive rate.
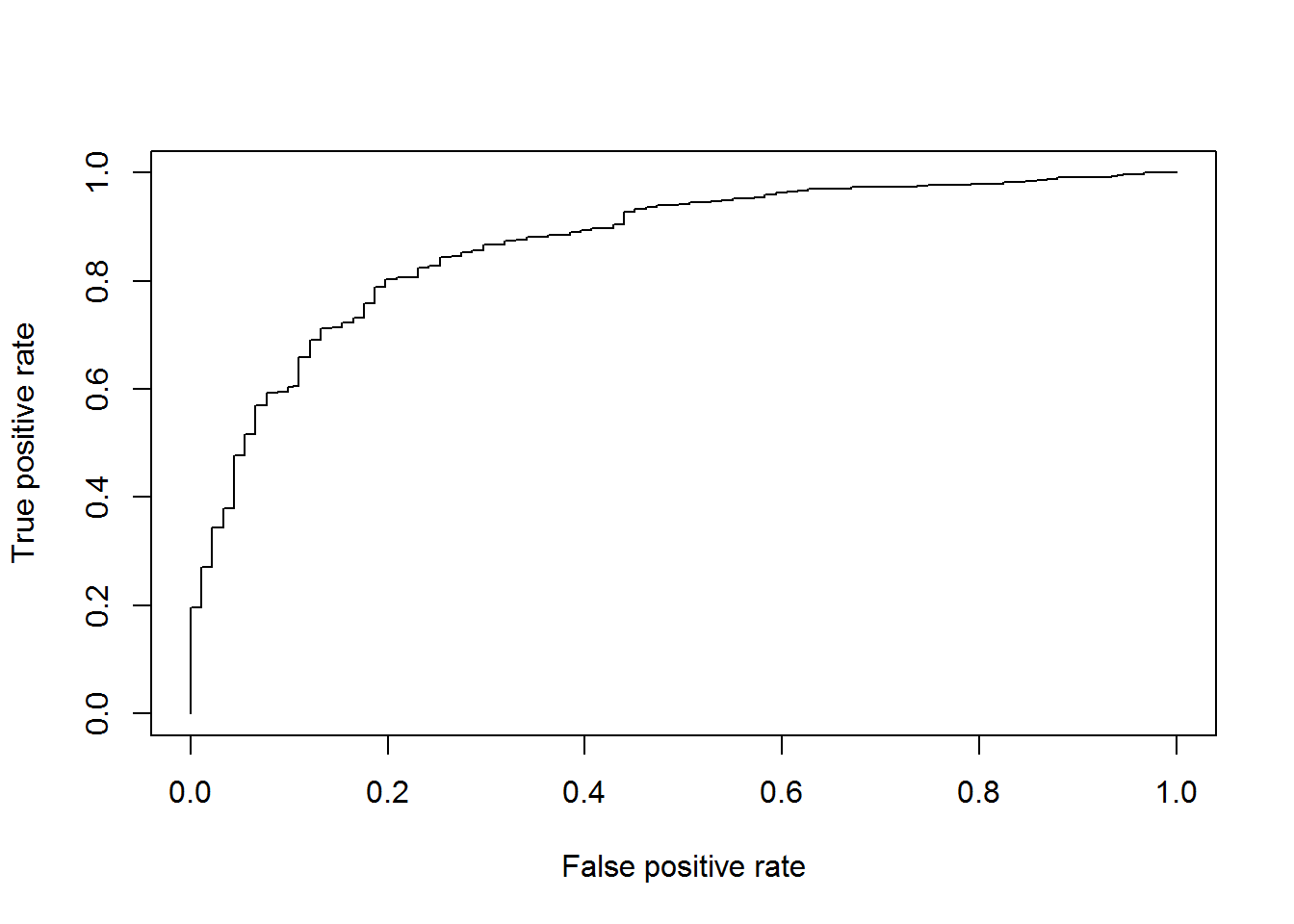
ROC Curve
2. Sự biến đổi của Sensitivity và False positive rate khi thay đổi Threshold.
Chúng ta thấy đường cong ROC là một dạng đường cong lồi hướng về phía góc trên cùng bên trái. Ứng với mỗi giá trị Sensitivity cao hơn là tỷ lệ False positive rate cao hơn. Điều này có thể lý giải như sau:
Khi các điểm cutpoint tăng dần thì tỷ lệ Sensitivity giảm dần do ở mức điểm cao hơn thì số lượng được dự báo là positive có thể giảm trong khi số lượng positive thực tế không đổi -> Sensitivity có thể giảm. Đồng thời tỷ lệ False positive rate tăng do mức điểm cao hơn thì số lượng dự báo là positive tăng -> số lượng được dự báo sai FP (Failse Positive) có thể tăng -> Tỷ lệ False positive rate tăng. Ta có thể giải thích điều này bằng hình ảnh mình họa:
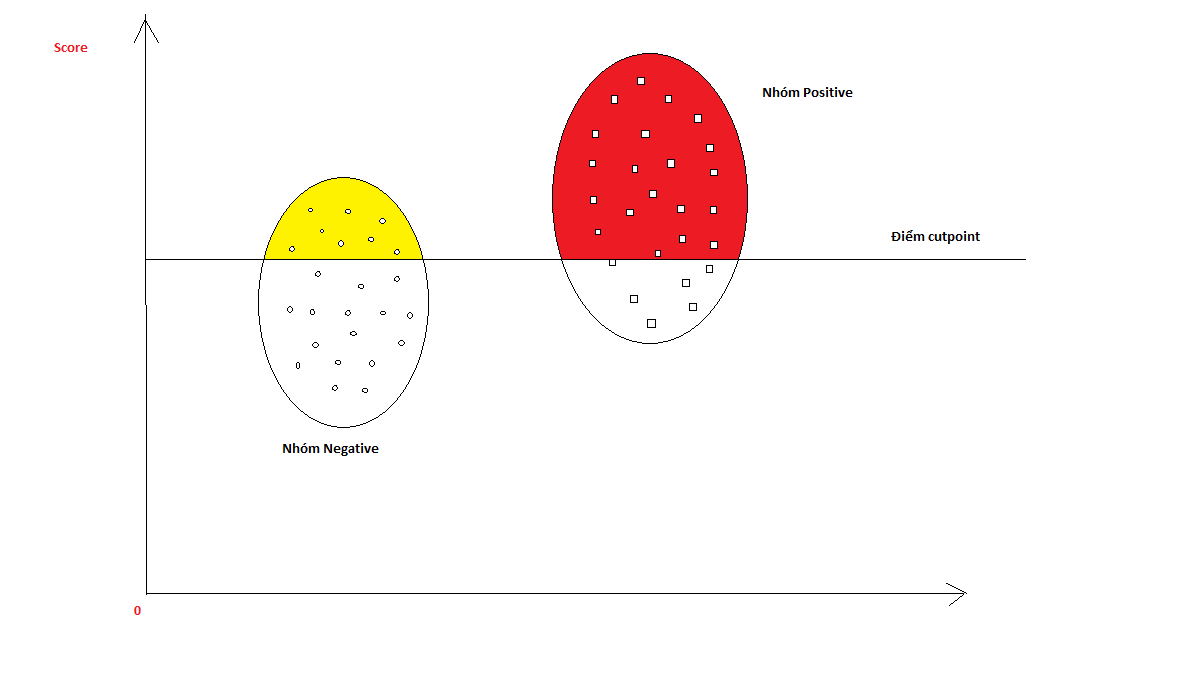
Cutpoint or Threshold
Hình elip1 chứa các chấm bi đại diện cho nhóm negative và hình elip2 chứa các chấm hình vuông đại diện cho nhóm positive. Điểm số của nhóm positive thu được từ model hồi qui sẽ có xu hướng cao hơn nhóm negative nên hình elip2 có xu hướng cao hơn elip1. ngưỡng cutpoint1 được thiết lập để phân chia những quan sát có điểm lớn hơn nó là positive (phần diện tích màu đỏ) và những quan sát có điểm nhỏ hơn nó là negative (phần diện tích màu vàng). Khi đó tỷ lệ Sensitivity sẽ bằng phần diện tích màu đỏ so với diện tích toàn bộ hình elip2 và Failse positive rate sẽ là phần diện tích màu vàng so với toàn bộ hình elip1. Khi ngưỡng cutpoint tăng dần thì diện tích màu đỏ và diện tích màu vàng đều giảm tương ứng với Sensitivity và Failse to positive đều giảm và ngược lại. Do đó đồ thị ROC có xu hướng đồng biến giữa Sensitivity và Failse to positive.
Bên cạnh tính đồng biến là tính lồi của ROC. Tính chất này sẽ không chứng minh ở đây do khá phức tạp về mặt toán học. Chúng ta chỉ cần hiểu đơn giản nó phản ánh ở các mức cutpoint (Threshold) thấp hơn thì mức độ gia tăng của Sensitivity cao hơn Failse to positive và mức cutpoint (Threshold) cao hơn thì xu hướng này ngược lại.
Đồ thị ROC biểu diễn tỷ lệ Sensitivity và Failse to positive của vô số các ngưỡng Threshold. Vậy tiêu chí nào có thể sử dụng để thiết lập một điểm Threshold tốt nhất cho một model. Và căn cứ vào đồ thị ROC thế hiện như thế nào thì ta sẽ xác định model có tính phân loại tốt nhất. Mục bên dưới sẽ trả lời cho câu hỏi này.
IV. Tiêu chuẩn lựa chọn model dựa trên ROC.
Giả sử chúng ta có 4 kết quả từ 4 model hồi qui lần lượt là A,B,C,C’ trên cùng một tập dữ liệu như bên dưới.
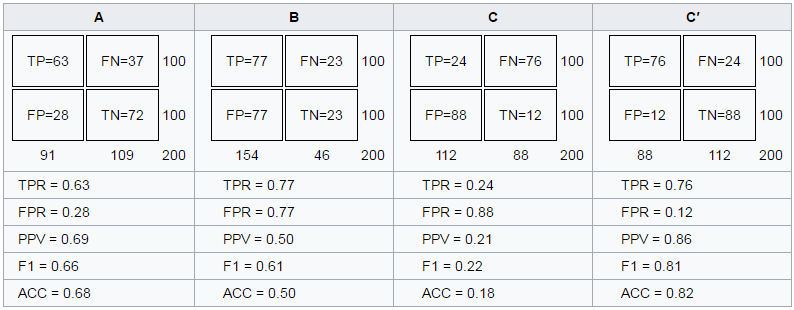
Accuracy table
Các tỷ lệ TP, FN, FP, TN, TPR, FPR được giải thích ở các mục I, II. Chúng ta thể hiện kết quả dự báo của 4 model này trên đồ thị ROC.
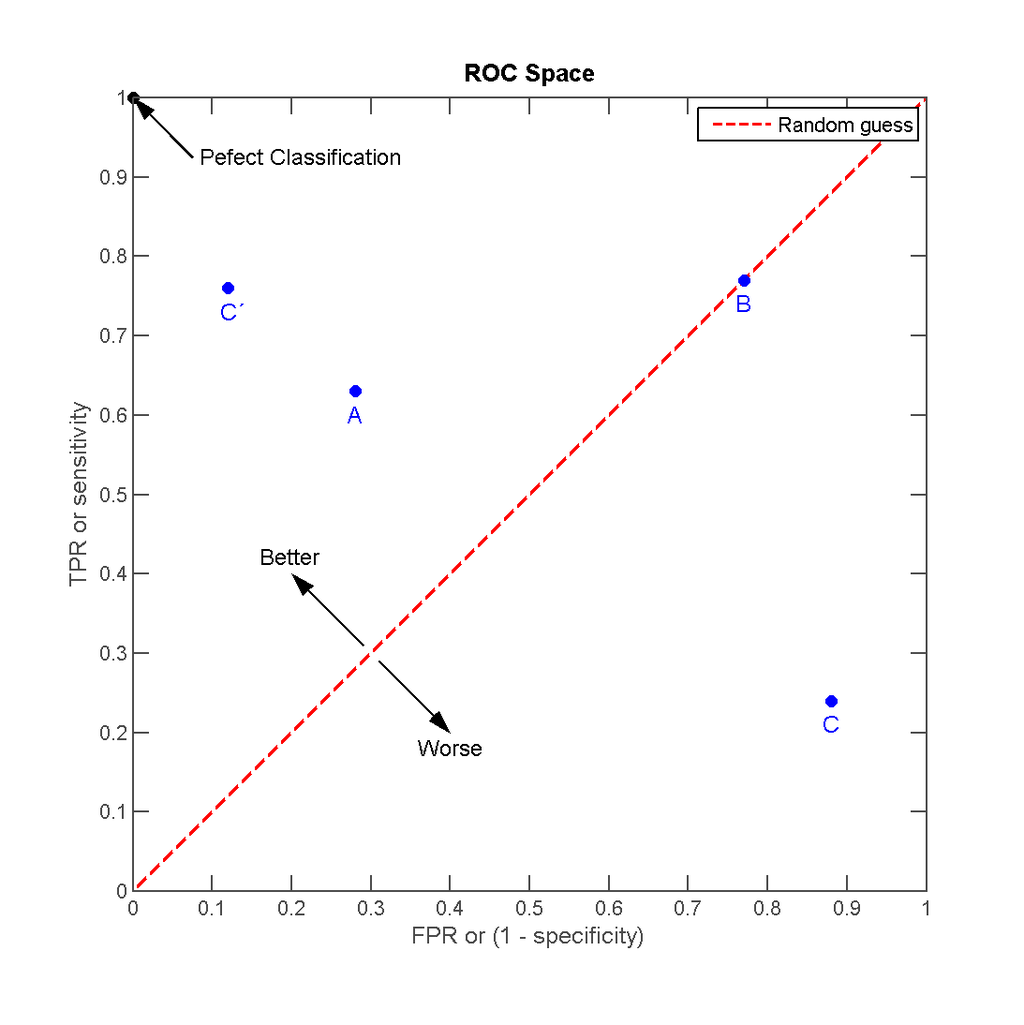
ROC Curve
Phương pháp dự báo A thể hiện kết quả tốt nhất trong các model A,B,C khi tỷ lệ Accuracy = 0.68. Kết quả dự báo của B là điểm B nằm trên đường dự báo random line (trùng với đường chéo) có Accuracy = 0.5. Đây là kết quả của việc dự báo ngẫu nhiên (trong trường hợp chưa biết xác xuất xảy ra của positive và negative).c là model có tỷ lệ Accuracy thấp nhất và kết quả dự báo này có tỷ lệ chính xác kèm hơn dự báo random. Tuy nhiên khi C được phản chiếu qua điểm trung tâm là (0.5,0.5) kết quả thu được là model C’ tốt hơn A. Kết quả phản chiếu đơn giản là đảo ngược dự báo của model C từ Positive thành Negative. Một model dự báo chính xác càng cao thì điểm biểu diễn của nó trên đồ thị ROC càng gần góc bên trái trên cùng. Tuy nhiên trên thực tế lựa chọn model phù hợp không hẳn chỉ căn cứ vào đồ thị của ROC mà xét đến giá trị rủi ro có thể tránh khỏi của model như đã đề cập ở mục I. Việc xác định 2 đồ thị ROC của 2 model xem đồ thị nào cong hơn chỉ mang tính tương đối vì vậy chỉ số chính xác hơn cả để đánh giá sức mạnh của model lại là khoảng cách của điểm đó với đường random line, khoảng cách này lớn hơn thì đồ thị ROC thể hiện sức mạnh phân loại cao hơn. Khi điểm này trùng với đỉnh của góc trên cùng bên trái tức là model dự báo perfect classification: Sensitivity = 100% và False positive rate = 0% và đối diện với nó qua điểm trung tâm (0.5,0.5) là điểm góc dưới cùng bên phải thể hiện model dự báo kết quả hoàn toàn sai: Sensitivity = 0% và False positive rate = 100%.
Một model có sức mạnh dự báo lớn hơn so với việc dự báo random khi nó có ROC nằm phía trên bên trái đường random line. Giá trị cutpoint tốt nhất để phân loại Positive và Negative cho model là điểm tiệm cận của đường thẳng song song với đường random line với ROC curve.
Tài liệu tham khảo
PyTorch là một thư viện tensor được tối ưu hóa để học sâu bằng GPU và CPU. Nhóm Meta AI của Facebook đã phát triển.
Tài liệu tham khảo
Keras được tạo ra để triển khai Deep Learning của TensorFlow trên Python.
Tài liệu tham khảo
TensorFlow giúp người mới bắt đầu và các chuyên gia dễ dàng tạo các mô hình máy học cho máy tính để bàn, thiết bị di động, web và đám mây. Nhóm Google Brain đã phát triển TensorFlow, một thư viện nguồn mở cho tính toán số.
Tài liệu tham khảo
Gói tin (Packet) là một đơn vị truyền kỹ thuật số có độ dài hữu hạn (thường là vài chục đến vài nghìn Octet) bao gồm trường tiêu đề (Header) và trường dữ liệu (Data). Trường dữ liệu có thể chứa hầu như bất kỳ loại dữ liệu kỹ thuật số nào. Các trường tiêu đề truyền tải thông tin liên quan đến việc phân phối và giải thích nội dung gói. Thông tin này có thể, xác định nguồn hoặc đích của gói, xác định giao thức được sử dụng để diễn giải gói, xác định vị trí của gói trong chuỗi các gói, cung cấp tổng kiểm tra sửa lỗi hoặc hỗ trợ kiểm soát luồng gói.
Mã hóa (Encryption) là quá trình mã hóa một tin nhắn hoặc thông tin theo cách mà chỉ các bên được ủy quyền mới có thể truy cập nó. Bản thân mã hóa không ngăn cản sự can thiệp, nhưng từ chối nội dung dễ hiểu đối với người dùng trái phép. Về cơ bản, mã hóa là một hình thức để ẩn một tin nhắn để không cung cấp nội dung thực tế/nguyên bản của nó cho một bên trung gian không được phép biết tin nhắn/nội dung thực tế.
Trong lược đồ mã hóa, tin nhắn hoặc thông tin dự định, được gọi là bản rõ (Plain-Text), được mã hóa bằng thuật toán mã hóa, tạo ra văn bản mật mã (Cipher-Text) chỉ có thể đọc được nếu được giải mã. Vì lý do kỹ thuật, lược đồ mã hóa thường sử dụng khóa mã hóa giả ngẫu nhiên do thuật toán tạo ra. Về nguyên tắc, có thể giải mã tin nhắn mà không cần sở hữu khóa, nhưng, đối với lược đồ mã hóa được thiết kế tốt, cần có các tài nguyên và kỹ năng tính toán đáng kể, đôi khi, có thể mất một khoảng thời gian dài trong nhiều năm tính toán bằng cách sử dụng máy tính rất đắt tiền và mạnh mẽ, trong nhiều trường hợp, không khả thi hoặc không khả thi về mặt kinh tế. Nhưng mặt khác, người nhận tin nhắn được ủy quyền sở hữu khóa giải mã có thể dễ dàng giải mã tin nhắn bằng cách sử dụng khóa do người khởi tạo cung cấp.
Chương trình máy tính (Computer Program) còn được gọi là Ứng dụng phần mềm (Software Application) hoặc Mã thực thi (Executable Code), được định cấu hình để thực thi trong một hệ điều hành cụ thể và mã thực thi đó có thể được thực thi trong bất kỳ máy nào chạy hệ điều hành đó. Do đó, cho phép một chương trình đơn lẻ (tức là mã thực thi), được viết một lần và được thực thi trong bất kỳ máy nào chạy cùng một hệ điều hành. Đây là cơ chế hiện đang được sử dụng nằm trong cốt lõi của công nghệ máy tính, mà chúng ta sử dụng trong cuộc sống hàng ngày.
Chiếm quyền điều khiển trình duyệt (Browser Hijacking) bao gồm bất kỳ phần mềm độc hại (Malware) nào ghi đè lên công cụ tìm kiếm mặc định của trình duyệt hoặc định tuyến lại lưu lượng truy cập Web trên máy để thu hút lưu lượng truy cập đến một trang Web cụ thể. Các bên thứ ba có thể mua lưu lượng truy cập này hoặc tìm cách lây nhiễm Bootstrap (ví dụ: bằng cách hướng lưu lượng truy cập đến các Driver-by Download) hoặc cho các luồng doanh thu khác, chẳng hạn như quảng cáo hoặc lừa đảo sản phẩm.
Tài liệu tham khảo:
1. Grier, Chris & Ballard, Lucas & Caballero, Juan & Chachra, Neha & Dietrich, Christian & Levchenko, Kirill & Mavrommatis, Panayiotis & Mccoy, Damon & Nappa, Antonio & Pitsillidis, Andreas & Provos, Niels & Rafique, M Zubair & Rajab, Moheeb & Rossow, Christian & Thomas, Kurt & Paxson, Vern & Savage, Stefan & Voelker, Geoffrey. (2012). Manufacturing compromise: The emergence of exploit-as-a-service. Proceedings of the ACM Conference on Computer and Communications Security. 821-832. 10.1145/2382196.2382283.
Keylogger hay Keystroke Logger là một phần mềm hoặc thiết bị phần cứng dùng để theo dõi các phím trên bàn phím. Không thể phát hiện sự hiện diện của nó vì nó chạy ngầm và thông tin của nó không có trong danh sách các chương trình đang chạy trong trình quản lý tác vụ hoặc bảng điều khiển. Nó có thể được sử dụng để lấy thông tin rất bí mật như tên người dùng và mật khẩu trong trường hợp bạn đăng nhập vào tài khoản ngân hàng trực tuyến của mình.
Tài liệu tham khảo
1. M. Wazid et al., "A framework for detection and prevention of novel keylogger spyware attacks," 2013 7th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 2013, pp. 433-438, doi: 10.1109/ISCO.2013.6481194.
Dropper là một phần mềm độc hại được thiết kế để phân phối Malware đến máy tính hoặc điện thoại của nạn nhân. Dropper thường là Trojan, phần mềm độc hại được ngụy trang thành phần mềm hợp pháp hoặc phần mềm có ích cho người dùng. Ví dụ: Key Generator, Keygen.
Trong hầu hết các trường hợp, Dropper không thực hiện bất kỳ chức năng độc hại nào. Mục đích chính của Dropper là cài đặt các công cụ độc hại khác, cái gọi là Payload, trên thiết bị mục tiêu mà nạn nhận không phát hiện. Không giống như Downloader tải nhiều nội dung độc hại từ máy chủ của kẻ tấn công và không thông báo rõ ràng cho người dùng chính xác nội dung tải xuống, Dropper đã chứa sẵn chúng. Khi khởi chạy, nó trích xuất Payload và lưu vào bộ nhớ thiết bị. Dropper cũng có thể khởi chạy trình cài đặt Malware.
Payload của Dropper có thể chỉ chứa một phần mềm độc hại, hoặc chứa nhiều Malware. Các phần mềm độc hại trong Payload không nhất thiết phải được kết nối với nhau và có thể phục vụ các mục đích khác nhau. Chúng thậm chí có thể được phát triển bởi các nhóm tin tặc khác nhau. Chúng có thể chứa các tập tin vô hại nhằm che giấu việc cài đặt Malware.
Theo quy tắc, những Dropper mang theo các Trojan đã biết mà các tính năng bảo mật của thiết bị đích sẽ không phát hiện để chặn. Chúng cản trở việc phát hiện Malware ở giai đoạn tải xuống và vô hiệu hóa hệ thống phòng thủ trước khi cài đặt Payload của chúng. Cơ chế trung hòa phụ thuộc vào loại hệ điều hành mục tiêu. Ví dụ: Dropper cho Windows thường hủy kích hoạt kiểm soát tài khoản người dùng (UAC), nó chạy ngầm và thông báo xác nhận cho người dùng nếu một ứng dụng cố gắng thực hiện một hành động ảnh hưởng đến các thành phần hệ thống quan trọng.
Tài liệu tham khảo